

The site reliability engineering (SRE) concept originated at Google. The idea is closely related to the principles of DevOps. It’s an approach to IT operations. SRE teams use the software to manage systems, solve problems, and automate operations tasks in Kubernetes.
What is Site Reliability Engineering (SRE)?
SRE teams take the tasks that IT operations teams have done, often manually, and instead give them to engineers or ops teams who use tools and automation to solve problems and manage production systems.
It’s a valuable practice while creating scalable and highly reliable software systems. It helps organizations manage massive infrastructure through code, which is more scalable and sustainable for system admins managing hundreds of thousands of machines.
Why do we need SRE? Is it Important? And What Makes a Good SRE Team?
SRE acts like a bridge between software engineering and IT operations and fills the gap between them. Pretty much everywhere, SRE comes into play when it comes to preparing for failures in production systems. It ensures that the organization’s systems are scalable, reliable, predictable, and automated.
SRE also sets Service Level Indicators (SLIs), Service Level Objectives (SLOs), Service Level Agreement (SLA) that defines the real numbers on performance, the objectives your team must hit to meet that agreement, and how reliable the systems need to be for the end-users.
The primary goal of SRE is to improve performance and operational efficiency.
Amit Choudhary
So, an SRE is not just “an ops person who codes.” Instead, the SRE is another member of the development team with a different set of skills, particularly around deployment, configuration management, monitoring, metrics, etc. Just as an engineer developing a nice look and feel for an application must know how data is fetched from a data store, an SRE is not solely responsible for these areas. The entire team works together to deliver a product that can be easily updated, managed, and monitored. The need for a site reliability engineer naturally comes about when a team is implementing DevOps, but realizes they are asking too much of the developers and need a specialist for what the ops team used to handle.
Before we dig deeper into SRE and how SREs work with the development team, we need to understand how site reliability engineering functions within the DevOps paradigm.
Site Reliability Engineering vs DevOps and How SRE Works with DevOps?
At its core, site reliability engineering is an implementation of the DevOps paradigm. Just as continuous integration and continuous delivery (CI/CD) are applications of DevOps principles to software release, SRE is an application of these same principles to software reliability.
There are a wide variety of ways to define DevOps. Still, the traditional model is where the development (“devs”) and operations (“ops”) teams are separated, leading to the team that writes code not being responsible for how it works when customers start using it. The development team would “throw the code over the wall” to the operations team to install and support.
you can use SRE to adopt DevOps principles in the organization better and measure your implementation’s success.
ACCORDING TO GOOGLE’S APPROACH
To better understand how to combine the two, consider the following principles:
- Reduce organizational silos: SRE helps by sharing ownership across developers and operations teams. This is one of the main principles of a DevOps philosophy. When SREs focus on improving the detection of issues and applications’ performance, operations teams can focus on managing infrastructure, and developers can focus on feature improvements.
- Accept failure as normal: Like DevOps, SREs don’t pass the blame for failures and production incidents between the IT teams. No-blame postmortems are an SRE best practice that ensures that all incidents are used as learning opportunities. When the possibility of failure is normalized, teams can take more significant risks, potentially leading to greater innovations without fear of excessive setbacks or downtime.
- Implement gradual change: Like DevOps, SRE also encourages continuous improvement through change. SRE requires the changes to be small and frequent. As a result, any negative repercussions are less impactful, and low-risk enhancements can be readily tested and implemented.
- Leveraging tooling and automation: While DevOps encourages automation and technology adoption, SRE is focused on embracing consistent technologies and information access across the IT teams. This makes it easier to manage operations and reduces the chance of issues created by technological incompatibilities. This standardization also helps ensure that members across a team can collaborate better since tooling is uniform and is less likely to require specialized skill sets that some members lack.
- Measure everything: SRE combines metrics with feedback loops to measure operations and identify opportunities for improvement. It also builds in slack for risk and manual operations as needed, making it more predictable through measurement. By applying metrics data, teams can set appropriate targets while maintaining reasonable expectations of performance.
Site Reliability Engineering best practices you must follow while embracing the SRE culture.
When implementing SRE, it may take you some time to refine your strategy and customize practices to meet your operational needs. To help speed up this process, consider the following SRE principles and best practices.
1. Error Budgets
In a nutshell, an error budget is the amount of error that your service can accumulate over a certain period of time before your users start being unhappy. You can think of it as the pain tolerance for your users but applied to a particular dimension of your service: availability, latency, and so forth. To calculate the error budget, we have to use the SLI equation:
SLI = [Good events / Valid events] x 100
Now the percentage is expressed as SLI, and once you define an objective for each of those SLIs, that is your service-level objective (SLO), and the error budget is the remainder, up to 100.
For example, imagine that you’re measuring the availability of your home page. The availability is measured by the number of requests responded with an error, divided by all the valid requests the home page receives, expressed as a percentage. If you decide that the objective of that availability is 99.9%, the error budget is 0.1%. You can serve up to 0.1% of errors (preferably a bit less than 0.1%), and users will happily continue using the service.

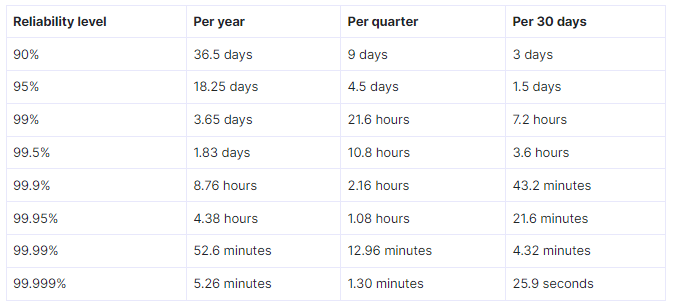
At first glance, error budgets don’t seem that important. They’re just another metric IT and DevOps need to track to make sure everything’s running smoothly, right? The answer, fortunately, is no. Error budgets aren’t just a convenient way to make sure you’re meeting contractual promises. The new updates are usually frozen if the team exhausts its error budget for a particular quarter. They’re also an opportunity for development teams to innovate and take risks.
2. Define SLOs Like a User
Measure availability and performance in terms that matter to an end-user. Service Level Objectives or SLOs are the fundamental basis of all Site Reliability Engineering. You can’t have error budgets, prioritize development work, or do timely and effective incident management without them. SLOs should specify how they’re measured and the conditions under which they’re valid. Read more about Service Level Objectives here.
Service Level Indicators (SLIs): A carefully defined quantitative measure of some aspect of the level of service provided, such as throughput, latency. It also:
- Directly measurable & observable by the users.
- This could represent the user’s experience.
- In simple words, this talks about what exactly you are going to measure.
Service Level Objectives (SLOs): A target value or range of values for a service level measured by SLI. It also:
- Defines how the service should perform from the perspective of the user (measured via SLI). In simple words, how good should services be? A threshold beyond which an improvement of the service is required.
- The point at which the users may consider opening up a support ticket.
- Driven by business requirements, not just current performance.
Service Level Agreements (SLAs): SLAs are:
- A business contract to provide a customer some form of compensation if the service did not meet expectations.
- In simple words, SLO + consequences.
3. Monitoring Errors and Availability
To identify performance errors and maintain service availability, SRE teams need to see what’s going on in their systems. Monitoring is required to verify an application/system is behaving as expected. This means a service, meeting specific goals, and understanding what happens when a change is made. Moreover, we want to know before the customer.
4. Efficiently Planning Capacity
Organizations need to plan for things like organic growth, which could be increased product adoptions, inorganic growth, which comes from sudden jumps in demand due to feature launches, marketing campaigns, etc. That will consume more resources (like outages on Black Friday or Cyber Monday). To prepare for these events, you’ll need to forecast the demand and plan time for acquisition.
Important facets of capacity planning include regular load testing and accurate provisioning. Regular load testing allows you to see how your system operates under the average strain of daily users. Also, adding capacity in any form can be expensive, so knowing where you need additional resources is the key.
5. Paying Attention to Change
Management
At many organizations, most outages are caused by changes to a live system, whether that’s going to a new binary push or a new configuration push. Every little change impacts the business. Therefore, analyze each change for the risk it carries. It should be supervised. Consider the impact of the long haul changes by seeing the big picture, not just how they can affect the system today.
To ensure that nothing unexpected occurs during the change, it must be monitored either by the engineer performing the rollout stage or preferably a demonstrably reliable monitoring system. If unexpected behavior is detected, roll back first and diagnose afterward to minimize Mean Time to Recovery (MTTR).
6. Blameless Postmortem
A truly blameless postmortem culture helps to build a more reliable system in organizations. Postmortems should be blameless and focus on process and technology, not people.
Assume the people involved in an incident are intelligent, are well-intentioned, and were making the best choices they could given the information they had available at the time. Pinning an incident on one person or a group of people is counterproductive. It creates an environment where people are afraid to take risks, innovate, and problem solve.
Failures will happen. There’s no way around it. But, by having a good incident resolution and retrospective practice in place, failures can be beneficial. It uncovers areas to focus on to improve resiliency. As long as you learn from an incident, you’ve made progress.
7. Toil Management
One of the main focuses of SRE is automation. Toil is a waste of precious engineering time, and by SREs creating frameworks, processes, internal tooling/building tooling to eliminate it, engineers can get back to innovating.
Conclusion
This blog post attempted to cover the fundamental concepts and practices required to build a successful SRE team. If you’re planning to adopt SRE culture in your project/organization, train your team, follow the best practices, and trust the process. You won’t achieve 100% perfection. That’s a myth. But you will make things a lot streamlined and get as close to perfection as possible.
Check Out Sportsfeed for Sports News, Reviews & More. Shaurya Loans Cityhawk Fauji Farms City Hawks Sports
So, This was How to Really Master Kubernetes? Also, Check The right path to learn Kubernetes from scratch to advanced?
If you need help with your Website Development or Digital Marketing, discover our Services.

