

One of the difficulties as Kubernetes applications expand the proliferation of services. As the amount of services rises, developers start to practice working with particular services. However, when troubleshooting, developers need to find the source, know the service and dependencies, and converse with the owning team for any support & Kubernetes annotations.
Human service discovery
Troubleshooting always starts with knowledge gathering. While much consideration is given to assembling machine data (e.g., logs, metrics), enormously less attention has been shown to the personal aspect of service development.
- Who owns an appropriate service?
- What Slack channel makes teamwork on?
- Where is the cause for the service?
- What issues are currently recognized and being hunted?
What are Kubernetes annotations?
Kubernetes annotations are intended to solve this problem correctly. Oft-overlooked, Kubernetes annotations are designed to add metadata to Kubernetes targets.
According to the official site
The Kubernetes documentation assumes annotations can “connect arbitrary non-identifying metadata to objects.” This indicates that annotations should be used to connect metadata external to Kubernetes (i.e., metadata Kubernetes won’t use to recognize objects).
Annotations can include any data. This is a contradiction to labels, which are intended for uses private to Kubernetes.
Annotation structure and conditions are constrained so Kubernetes can efficiently utilise them.
Kubernetes Services for Humans
Annotations are practised for “non-identifying information,” i.e., metadata that Kubernetes does not bother about. As such, annotation signs and values have no restrictions. Thus, annotations are more valuable if you want to add data for other individuals about a given resource.
The following mild example applies both annotations and a selector. The annotations are practiced to add knowledge about the Kubernetes service for humans and are not handled by Kubernetes. The selector is practiced by the Kubernetes service to recognize resources that the service will route to.

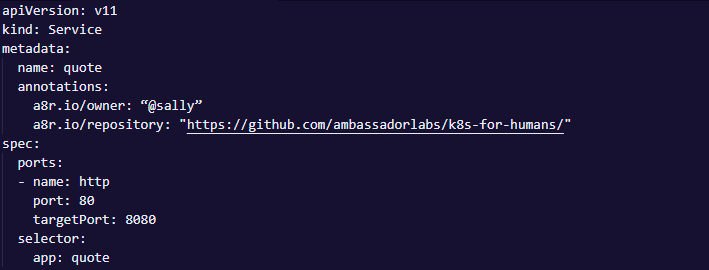
Examples of data that could be written in annotations:
- Fields directed by a declarative configuration panel. Appending these disciplines as annotations distinguishes them from default values set by customers or servers and from auto-generated areas and ranges set by auto-sizing or auto-scaling policies.
- Create, release, or image data like timestamps, propaganda IDs, git branch, PR amounts, image hashes, and registry location.
- Pointers to logging, monitoring, analytics, or audit repositories.
- Consumer library or tool knowledge that can be practiced for debugging ideas: for instance, name, version, and build knowledge.
- User or tool/system provenance data, such as URLs of related objects from different ecosystem elements.
- Lightweight rollout device metadata: for instance, config or checkpoints.
- Phone or pager products of persons engaged or directory entries specify where that data can be found, before-mentioned as a team website.
- Directives from the end-user to the implementations to correct course or engage non-standard characteristics.
Annotating Kubernetes Services for Humans
This Table below outlines a convention for using annotations to help developers manage Kubernetes services.
| ANNOTATION | DESCRIPTION |
|---|---|
| a8r.io/description | Unstructured text description of the service for humans. |
| a8r.io/chat | Slack channel (prefix with #), or link to another external chat system. |
| a8r.io/bugs | Link to the external bug tracker. |
| a8r.io/logs | Link to external log viewer. |
| a8r.io/documentation | Link to external project documentation. |
| a8r.io/repository | Link to external VCS repository. |
| a8r.io/support | Link to the external support center. |
| a8r.io/runbook | Link to the external project runbook. |
| a8r.io/incidents | Link to the external incident dashboard. |
| a8r.io/uptime | Link to external uptime dashboard. |
| a8r.io/performance | Link to external performance dashboard. |
| a8r.io/dependencies | Unstructured text description of the service dependencies for humans. |
kubectl annotate.Advantages Of Kubernetes Annotations:
Arranging, planning, and cataloguing your artifacts
You will unquestionably have many artifacts to operate as your environment expands with your firm. These artifacts will arise from separate pipelines and will be assigned for various purposes. Annotators implement a straightforward way to tag your antiques, so you can control and manage them more comfortably.
Promote development lifecycle & ensure compliance
You may try to implement various agreement rules as part of your development lifecycle, and you can leverage annotators to do so.
One real-life model is using an “owner” annotator (or similar designation). You may need your developers to charge an owner to every model. If anything should go incorrect with its container, you can immediately recognize the suitable means to remedy the problem.
Automating deployments
The data you store in annotators may also designate how to deploy the workload. Consider a situation where a set of workloads within your application need to remain behind a particular proxy server; you add a “HasProxy” annotator to your concepts, and any container requiring to be extended behind a proxy will be assigned the value “true.”
Check Out Sportsfeed for Sports News, Reviews & More. Shaurya Loans Cityhawk Fauji Farms City Hawks Sports
Conclusion
Kubernetes annotations are a unique way of classifying and arranging Kubernetes objects and supplies. Kubernetes team leads and IT managers are best placed on developing and implementing Kubernetes annotation plans. By ensuring annotation conventions are followed across teams, they can tame Kubernetes environments and prevent sprawl. Since annotations make it easier to operate on Kubernetes objects in bulk, adhering to annotation conventions will also make teams more productive in the long run.
So, This was Annotating Kubernetes Services For Humans Also, Check New OpenSource Alternative to Datadog?
If you need help with your Website Development or Digital Marketing, discover our Services.


2 comments